👉🏻리스트 자료형
- 여러 개의 데이터를 연속적으로 담아 처리하기 위해 사용하는 자료형
- 사용자 입장에서 C나 자바에서의 배열(Array)의 기능 및 연결 리스트와 유사한 기능을지원한다.
- C++의 STL vector, Java의 Array List와 기능적으로 유사하다
- 리스트 대신에 배열 혹은 테이블이라고 부르기도 한다.

🧩 일반 배열과 비교했을 때 더 다양하고 유용한 기능 제공
- .append(): 연속적인 데이터가 메모리에 올라가 있을 때 그 뒷쪽에 반복적으로 데이터를 이어 붙일 수 있는 기능
- 뒷쪽에서 데이터를 제거하는 기능 제공
- 여러개의 유사한 성질을 가진 데이터가 연속적으로 담겨야할 때 많이 사용
➡️테이블이라고도 부름
- 그냥 배열의 기능을 이용하고자 할 때
➡️배열이라고 부름
🧩리스트 초기화
- 리스트는 대괄호([])안에 원소를 넣어 초기화하며, 쉼표(,)로 원소를 구분한다
- 비어 있는 리스트를 선언하고자 할 때는 list() 혹은 간단히 []를 이용할 수 있다
- 리스트의 원소에 접근할 때는 인덱스(Index) 값을 괄호에 넣는다
- 인덱스는 0부터 시작한다.
# 직접 데이터를 넣어 초기화
a = [1, 2, 3, 4, 5, 6, 7, 8, 9]
print(a)
# 네 번째 원소만 출력
print(a[3])
# 크기가 N이고, 모든 값이 0인 1차원 리스트 초기화
n = 10
a = [0] * n
print(a)
a = [7, 3, 2, 5, 9]
# 0 1 2 3 4
print(a)
# 특정 위치 요소의 값 바꾸기
a[4] = 4
print(a)
🧩 리스트의 인덱싱과 슬라이싱
- 인덱스 값을 입력하여 리스트의 특정한 원소에 접근하는 것을 인덱싱(Indexing)이라고 한다.
- 파이썬의 인덱스 값은 양의 정수와 음의 정수를 모두 사용할 수 있다
- 음의 정수를 넣으면 원소를 거꾸로 탐색하게 된다.
- 유의할 점: 음의 정수를 넣을 때는 -1부터 차례대로 작아지는 방식으로 원소에 접근할 수 있다.
a = [1, 2, 3, 4, 5, 6, 7, 8, 9]
# 여덟 번째 원소만 출력
print(a[7])
# 뒤에서 첫 번째 원소 출력
print(a[-1])
# 뒤에서 세 번째 원소 출력
print(a[-3])
# 네 번째 원소 값 변경
a[3] = 7
print(a)
- 리스트에서 연속적인 위치를 갖는 원소들을 가져와야 할 때는 슬라이싱(Slicing)을 이용한다
- 대괄효 안에 콜론(:)을 넣어서 시작 인덱스와 끝 인덱스를 설정할 수 있다.
- 끝 인덱스는 실제 인덱스보다 1을 더 크게 설정해야 한다.
- 다른 언어에서는 더 복잡하게 가져와야함 (별도의 함수를 이용하거나 정의해서)
a = [1, 2, 3, 4, 5, 6, 7, 8, 9]
# 네 번째 원소만 출력
print(a[3])
# 두 버째 원소부터 네 번째 원소까지
print(a[1:4])
🧩 리스트 컴프리헨션
- 리스트를 초기화하는 방법 중 하나이다
- 대괄호 안에 조건문과 반복문을 적용하여 리스트를 초기화 할 수 있다.
- 파이썬이 제공하는 강력한 기능
array = [i for i in range(10)]
print(array)
- i라는 변수가 0 ~ 9까지 증가하며 반복할 때 마다(?) i의 값들을 원소로 설정해서 리스트를 만들겠다
- range(10) = 0 ~ 9까지의 수
# 0부터 19까지의 수 중에서 홀수만 포함하는 리스트
array = [i for i in range(20) if i % 2 == 1]
print(array)
# 1부터 9까지의 수들의 제곱 값을 포함하는 리스트
array = [i * i for i in range(1, 10)]
print(array)
- 음이 아닌 정수 i를 2로 나누었을 때 나머지가 1이라면 i는 홀수이다
🧐 리스트 컴프리헨션과 일반 코드 비교
# 리스트 컴프리헨션
# 0부터 19까지의 수 중에서 홀수만 포함하는 리스트
array = [i for i in range(20) if i % 2 == 1]
print(array)
# 일반적 코드
# 0부터 19까지의 수 중에서 홀수만 포함하는 리스트
array = []
for i in range(20):
if i % 2 == 1:
array.append(i)
print(array)
- 여러 줄의 코드를 한 줄 만으로 해결
- 리스트 컴프리헨션은 2차원 리스트를 초기화할 때 효과적으로 사용될 수 있다.
- 특히 N × M 크기의 2차원 리스트를 한 번에 초기화 해야 할 때 매우 유용하다
- 좋은 예시: array = [[0] * m for _ in range(n)]
- 만약 2차원 리스트를 초기화할 때 다음과 같이 작성하면 예기치 않은 결과가 나올 수 있다.
- (의도하지 않았다면) 잘못된 예시: array = [[0] * m] *n
- 위 코드는 전체 리스트 안에 포함된 각 리스트가 모두 같은 객체로 인식된다
- 문제 상황을 N × M 의 맵 상에서 다뤄지는 문제가 많다
- n번 반복할 때 마다 길이가 m인 리스트를 새롭게 초기화해서 n * m 크기의 2차원 리스트 탄생
- 파이썬은 기본적으로 리스트 자료형을 이용해서 어떤 변수 값을 할당하게 되면 내부적으로 그 리스트는 객체 형태로 처리
- 별도의 주소 값을 가짐
- 단순히 리스트 자체를 n번 곱하도록 만들게 되면 내부적으로 길이가 m인 리스트를 n번 만큼 참조값 복사하는 것과 같다
- 즉, 모두 같은(동일한) 객체로 인식된다
- 내부 리스트에서 특정 위치에 하나의 값만 바꾸더라도 모든 리스트에 변경사항이 적용된다
👍🏻 좋은 예시
# N X M 크기의 2차원 리스트 초기화
n = 4
m = 3
array = [[0] * m for _ in range(n)]
print(array)
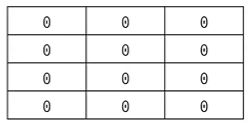
- 행 4 * 열 3
- n번 반복 할 때 마다 길이가 m인 리스트를 매번 초기화해서 전체 2차원 리스트를 특정한 변수에 대입
- 특정한 위치의 값을 바꾸면 그 위치의 값만 바뀜
👎🏻나쁜 예시
# N X M 크기의 2차원 리스트 초기화 (잘못된 방법)
n = 4
m = 3
array = [[0] * m] * n
print(array)
array[1][1] = 5
print(array)
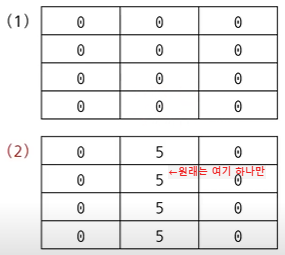
- 특정 위치를 바꾸려고 하면 모든 내부 리스트에서 해당 리스트의 해당 요소 값이 바뀜
👉🏻언더바(_)의 이용
- 파이썬에서는 반복을 수행하되 반복을 위한 변수의 값을 무시하고자 할 때 언더바(_)를 자주 사용한다
# 1부터 9까지의 자연수 더하기
summary = 0
for i in range(1, 10):
summary += i
print(summary)
# "Hello World"를 5번 출력하기
for _ in range(5):
print("Hello World")

- i의 값을 활용해야되냐 굳이 활용하지 않아도 괜찮냐의 차이인듯!
- 내부적으로 변수 값이 사용되지 않고 반복할 때, 단순히 내부적으로 어떤 작업을 반복하고자 할 때 언더바(_)
🧩 리스트 관련 기타 메서드

- append: 가장 뒷 쪽에 하나의 원소를 추가
- sort(): 리스트가 내부적으로 가지고 있는 변수를 자동 정렬
- 다른 언어는 removeall() 등의 함수를 별도로 제공하기도 함
- 파이썬은 별도로 코드를 작성해야함
# 리스트 관련 기타 메서드
a = [1, 4, 3]
print("기본 리스트:", a)
# 리스트에 원소 삽입
a.append(2)
print("삽입:", a)
# 오름차순 정렬
a.sort()
print("오름차순 정렬:", a)
# 내림차순 정렬
a.sort(reverse=True)
print("내림차순 정렬:", a)
a = [4, 3, 2, 1]
# 리스트 원소 뒤집기
a.reverse()
print("원소 뒤집기:", a)
# 특정 인덱스에 데이터 추가
a.insert(2, 3)
print("인덱스 2에 3 추가:", a)
# 특정 값인 데이터 개수 세기
print("값이 3인 데이터 개수:", a.count(3))
# 특정 값 데이터 삭제
a.remove(1)
print("값이 1인 데이터 삭제:", a)
- [1, 2, 3, 4]에서 인덱스 2는 3 → 2와 3 사이에 3이 추가됨
# 리스트에서 특정 값을 가지는 원소를 모두 제거
a = [1, 2, 3, 4, 5, 5]
remove_set = {3, 5}
# remove_list에 포함되지 않은 값만을 저장
result = [i for i in a if i not in remove_set]
print(result)
- remove()함수는 하나의 값만 제거하기 때문에 여러 값을 제거하려면 집합 자료형을 사용해야함
- 집합 자료형은 특정 원소의 존재 유무만을 체크하고자 할 때 효율적
- a의 원소 i를 하나씩 확인하면서 만약 그 i가 remove_set에 포함되어있지 않다면 result에 원소로 넣겠다
- 3, 5가 아닌 값들만 남기겠다
출처: https://youtu.be/GUwkMLtDQJE?si=SzxpCcsDl5XkYHnL
'Python > 이것이코딩테스트다with파이썬' 카테고리의 다른 글
| 7강 :: 기본 입출력 (0) | 2023.11.02 |
|---|---|
| 5~6강 :: 문자열, 튜플 자료형, 사전, 집합 자료형 (0) | 2023.11.01 |
| 3강 :: 파이썬 문법 수 자료형 (0) | 2023.09.11 |
| 2강 :: 알고리즘 성능 평가 (0) | 2023.09.07 |
| 1강 :: 코딩 테스트란 무엇인가? (1) | 2023.09.07 |