그래프 탐색 알고리즘: DFS / BFS
👉🏻 그래프 탐색 알고리즘: DFS / BFS
- 탐색(Search)이란 많은 양의 데이터 중에서 원하는 데이터를 찾는 과정을 말한다
- 대표적인 그래프 탐색 알고리즘으로는 DFS와 BFS가 있다
- DFS/BFS는 코딩 테스트에서 매우 자주 등장하는 유형이므로 반드시 숙지해야 한다
- 다양한 알고리즘에서 특정 조건에 맞는 데이터가 존재하는지, 존재한다면 어떤 위치에 존재하는지 찾고자 하는 목적으로 다양한 탐색 알고리즘을 사용한다
- 국내 대기업 공채에서는 DFS/BFS를 적절히 활용해야 하는 문제가 자주 출제됨
👉🏻 스택 자료구조
- 먼저 들어 온 데이터가 나중에 나가는 형식(선입후출)의 자료구조
- 입구와 출구가 동일한 형태로 스택을 시각화할 수 있다.

- 여러개의 박스를 쌓아야 할 때(stack) 아래부터 박스를차례로 올림
- 박스를 내리려고 할 때는 맨 위에 있는 박스부터 차례로 내림
- DFS뿐만 아니라 다양한 알고리즘에서 사용된다
🧩 스택 동작 예시
- 스택 자료구조는 '삽입'과 '삭제' 두 연산으로 구성


✅ list 자료형
- stack을 구현하기 위해 파이썬에서는 list 자료형을 활용
- append(), pop() 등을 지원함
✅ append()
- 가장 오른쪽에 원소를 삽입함
- 시간 복잡도 = 상수 시간 (O(1))
✅ pop()
- 가장 오른쪽에서 하나의 원소를 꺼냄
- 시간 복잡도 = 상수 시간 (O(1))
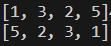
- 최상단 원소 = 가장 먼저 나갈 원소 = 리스트 내의 가장 오른쪽 원소
* C++ ver

* Java ver

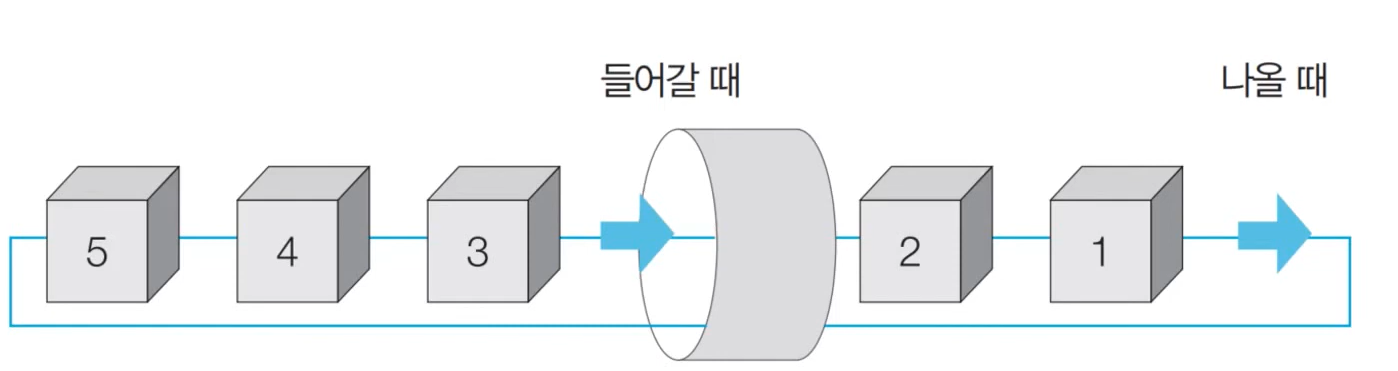
👉🏻 큐 자료구조
- 먼저 들어 온 데이터가 먼저 나가는 형식 (선입선출)의 자료구조
- 큐는 입구와 출구가 모두 뚫려 있는 터널과 같은 형태로 시각화할 수 있다
- 은행 창구 등에서 사람들이 번호표를 뽑고 대기하는 모습
- 대기열 (순서대로 처리)
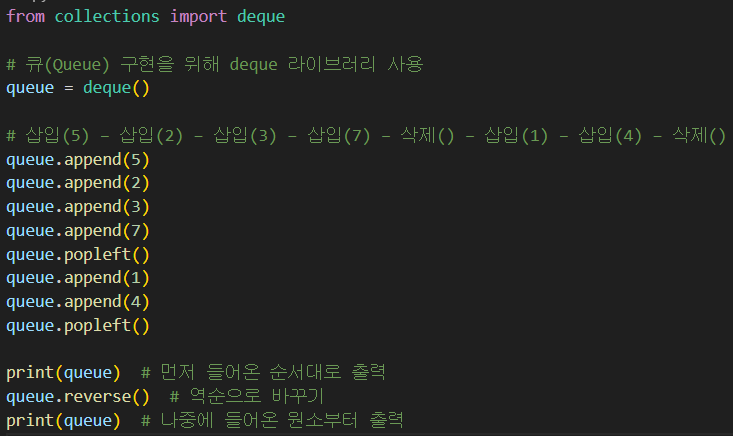
✅ deque 라이브러리
- 엄밀히 말하면 단순히 리스트 자료형을 이용해도 됨
- 기능적으로는 구현 가능하나 시간 복잡도가 높아 비효율적일 수 있음
- 하나의 deque 객체를 생성
- append(), popleft() 등을 이용하면 됨
- stack과 queue 자료구조의 장점을 모두 합친 형태의 자료구조
✅ append()
- 원소 삽입
- 리스트에서 append와 같이 가장 마지막, 가장 오른쪽에 하나의 원소 추가
- 시간 복잡도 = 상수시간
✅ popleft()
- 원소 삭제
- 가장 왼쪽 데이터 꺼낼 때
- 시간 복잡도 = 상수 시간
- 여기서 그려지는 형태는 앞 움짤과 반대 방향

🧩 리스트 이용
- 단순히 리스트를 이용해 특정 인덱스에 존재하는 원소를 꺼내기 위해 pop() 메서드를 호출하면
원소를 꺼낸 뒤에 원소 위치 조정하는 과정 필요
- 원소를 꺼내는 연산 자체가 O(k)만큼의 시간복잡도 요구됨
* C++ ver

* Java ver

출처: https://youtu.be/7iLoLcna7Hw?si=062D_iOfb_muCMeq
https://youtu.be/gFpKGWdEE5g?si=TWMmSZkRheIrREb8
'Python > 이것이코딩테스트다with파이썬' 카테고리의 다른 글
| 18~20강 :: DFS 알고리즘, BFS 알고리즘 (1) | 2023.11.27 |
|---|---|
| 17강 재귀 함수 (0) | 2023.11.22 |
| 14~15강 :: 구현 유형 개요 및 문제 풀이 (0) | 2023.11.15 |
| 12~13강 :: 그리디 알고리즘 개요와 문제 풀이 (0) | 2023.11.09 |
| 11강 :: 자주 사용되는 표준 라이브러리 (2) | 2023.11.09 |