03-2. 선형 회귀

* 머신 러닝 알고리즘은 지도학습과 비지도 학습으로 나뉨 (+ 강화학습)
* 지도학습은 분류와 회귀로 나뉜다
* 분류는 여러개의 클래스 중 하나를 구분해냄
* 회귀는 임의의 어떤 숫자를 예측
* 농어의 길이로 무게 예측
* 클래스가 아니라 무게(임의의 실수) 예측
* 분류: 가장 가까운 이웃 샘플의 클래스를 보고 다수인 클래스를 가지고 예측
* 회귀: 이웃한 샘플을 찾은 후 샘플의 타깃값(임의의 숫자)의 평균
* 분류일 경우 샘플 n개 중에 m개를 정확히 예측 - 맞은 비율을 정확도로 사용
* 회귀는 타깃과 예측값의 차이를 활용한 지표를 많이 사용 (R² = 사이킷런 score()메서드에서 제공하는 반환값)
* 훈련세트와 테스트세트에 각각 score()메서드 적용
→ 결과를 봤을 때 학습세트에 있는 내용(패턴)을 충분히 학습하지 못했다 판단 (과소적합)
* 테스트세트 점수가 더 높으면 훈련이 끝까지 안됐거나 모델이 너무 단순하거나
* 과소적합된 모델은 복잡도가 낮다
* 과대적합된 모델은 복잡도가 높다
* 과소적합과 과대적합이 되지 않도록 이웃의 개수를 조절해야함 (모델 복잡도 조절)

✏️ 아주 큰 농어
- k-최근접 이웃 회귀 알고리즘의 단점(문제점) 발견

- knr객체를 훈련시켜 농어를 넣어봤더니 1.03kg정도 예측됨
- 실제 무게를 재보니 1.5kg였음
- 왜 이런 문제가 발생할까?
🎮 50cm 농어의 이웃






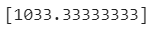
- 1033으로 예측!!

- kneighbors()메서드를 사용해 50cm 농어의 이웃의 거리와 인덱스를 구함
- (거리는 필요 없고) index만 가지고 numpy의 배열 인덱싱을 활용해 index 배열에 있는 원소들을 주황색으로 출력
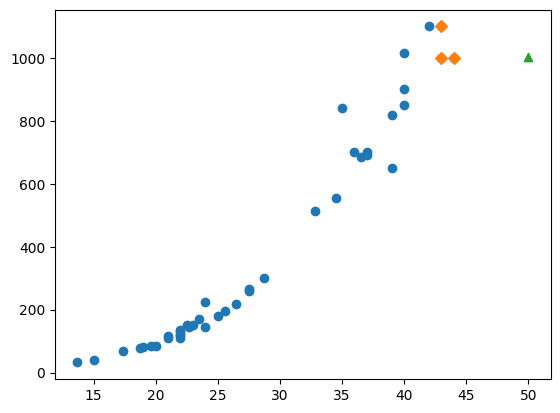
- (파)훈련 세트의 산점도, (주)50cm 농어의 최근접 이웃
- 길이가 늘어나면 무게도 늘어나야 하는데, 최근접 이웃은 가장 가까이 있는 샘플을 참고해서 예측하기 때문에
🎮 50cm 농어의 이웃들의 평균 무게

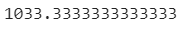
🎮 100cm 농어

- 100cm 농어의 무게를 예측해보기
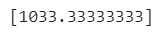
- 1.03kg으로 예측함

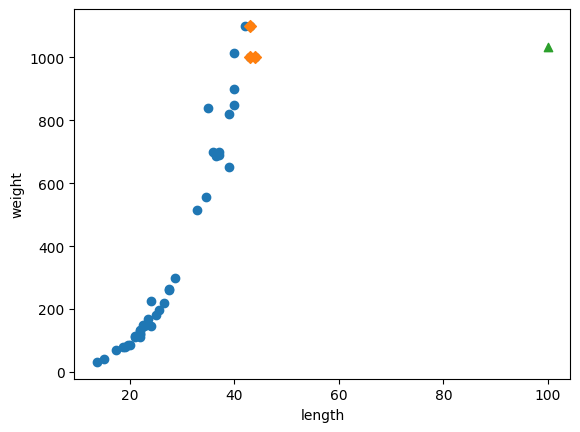
- 100cm짜리를 넣어도 최근접 이웃이 40cm근방에 있는 샘플들이다. 100cm 만큼 큰 생선의 샘플이 없음
- 최대값이 제한되면 잘못된 예측을 할 수 밖에 없다
* k-최근접 이웃 알고리즘은 훈련 세트에 있는 샘플 범위 바깥에 있는 값을 예측(추정)하기가 어렵다
* 추세를 따라갈 수 있는 알고리즘을 사용해야한다
* 그것이 바로 선형 회귀이다
👉🏻 선형 회귀(linear regression)
- 로지스틱회귀와 신경망도 선형회귀를 기반으로 한다
- 보기보다 강력한 모델
- 특성이 많을 때 강력한 성능을 낼 수 있다.
- 실전에서도 많이 사용된다
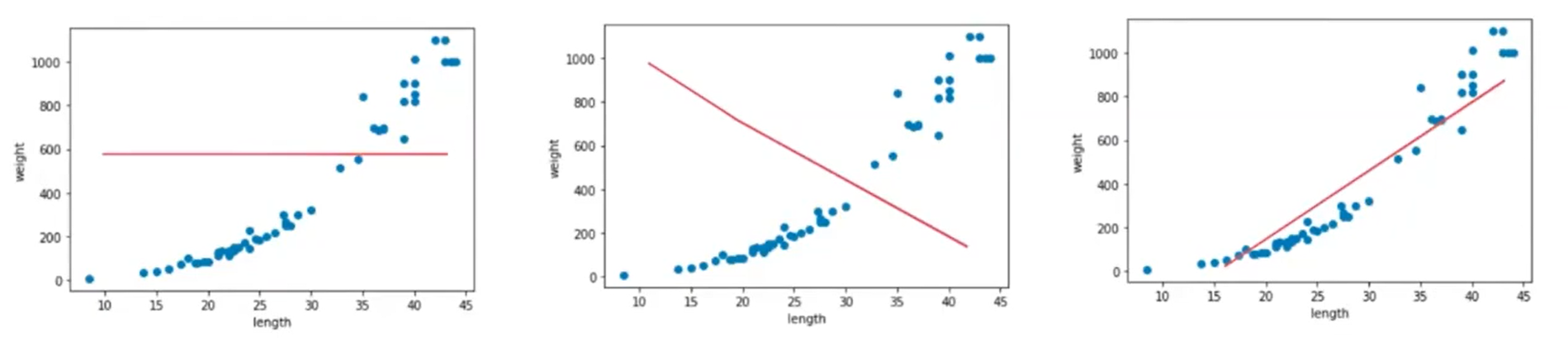
- 1차원 데이터(length 하나만 사용) : 직선의 방정식으로 나옴
- 당연히 세 번째 직선이 농어의 길이와 target(무게)를 잘 표현하는, 추세를 따라가는 직선이다!
- 3번 같은 직선을 찾는 것이 선형 회귀
- 예시는 쉬운 설명을 위해 특성을 하나만 활용한 것. 얼마든지 특성을 여러개 사용할 수 있다
🎮 Linear Regression

- 클래스 임포트
- 사이킷런 선형 모델들은 linear_model 모듈 안에 있다
- 선형 회귀 객체를 만들어준다
- 준비한 train_input과 train_target을 넣어 훈련시켜준다
- numpy 배열로 준비

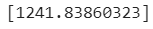
- 1.2kg 정도로 예측
- 최근접이웃으로 했을 때는 1.03kg 정도였던 것에 비교하면 확실히 추세를 잘 따르고 있음을 알 수 있다
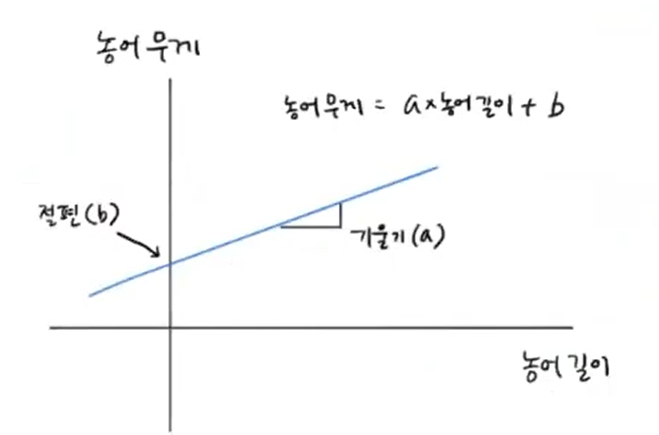
- 선형 모델이 학습한 것은 직선
- 직선의 방정식 (y = ax + b)
- a = 기울기, b = y 절편
- a와 b를 찾는 것이 선형회귀
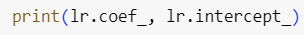
- a와 b를 찾는 방법은 lr 객체에 coef_와 intercept_라는 속성으로 구현(저장)되어 있음
- 어떤 데이터에서 학습한 값들을 저장할 때 다른 속성과 구분하기 위해 속성 이름 마지막에 언더바(_)를 추가
- 내가 지정한 값이 아니라 모델이 데이터로 부터 학습한 값이라고 이해하면 됨
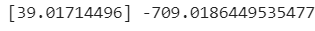
- 기울기: 39
- 리스트 형태로 나옴 (사실 넘파이 배열)
- 여기서는 길이 특성 하나만 활용했기 때문에 원소가 하나만 나온 것
- 여러개의 특성을 활용할 수 있고, 특성마다 여러개의 기울기/계수가 있음
- y절편: -709
- 하나라서 일반 스칼라값 / 실수값으로 나옴
사이킷런의 선형 회귀 모델에서 lr.coef_와 lr.intercept_는 각각 회귀 계수(coefficients)와 절편(intercept)을 나타냅니다. 이 두 가지는 선형 회귀 모델이 데이터를 잘 표현하기 위해 학습한 파라미터들입니다.
- lr.coef_ (회귀 계수):
- lr.coef_는 입력 특성(feature)들의 회귀 계수를 담고 있는 속성입니다.
- 각 특성은 모델이 예측을 수행할 때 그 중요도를 나타냅니다. 높은 절댓값의 계수는 해당 특성이 모델의 예측에 큰 영향을 미친다는 것을 의미합니다.
- 예를 들어, 만약 당신이 주택 가격을 예측하는 모델을 만들었다면, 각 계수는 방의 갯수, 주택의 크기 등과 같은 특성들과 어떤 관계에 있는지를 나타냅니다.
- lr.intercept_ (절편):
- lr.intercept_는 모델의 절편 값을 나타냅니다.
- 절편은 모든 특성이 0일 때의 예측값을 나타냅니다. 즉, 회귀 직선이 원점을 지나가지 않을 때의 보정 값이라고 생각할 수 있습니다.
- 예를 들어, 주택 가격을 예측하는 모델에서 절편은 모든 특성(방의 갯수, 주택의 크기 등)이 0일 때의 주택 가격을 나타냅니다.
간단히 말하면, lr.coef_는 각 특성의 영향력을, lr.intercept_는 모델의 기본 예측값을 나타냅니다. 이 값을 조합하여 모델이 주어진 입력에 대해 어떻게 예측을 수행하는지를 이해할 수 있습니다.
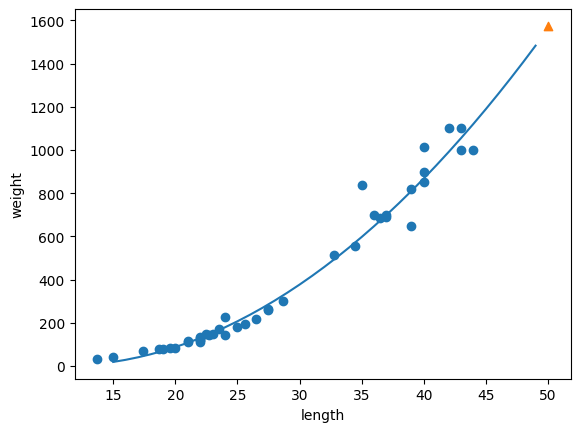
🎮 학습한 직선 그리기

- scatter() 함수로 훈련 세트의 산점도를 먼저 그림
- 더 길게 그려도 되지만 우리가 관심 있는 건 50cm 농어이기 때문에 15 ~ 50의 1차방정식을 그린다
- x좌표는 15 ~ 50으로 그리고
- y좌표는 15에 계수를 곱하고 절편을 더한 것 ~ 50에 계수를 곱하고 절편을 더한 것
15 * lr.coef_ + lr.intercept_는 x가 15일 때 선형 회귀 모델에 의해 예측된 y 값을 계산하는 것입니다. 이것은 선형 회귀 모델의 예측 방정식 y = ax + b에서 도출된 값으로서, lr.coef_는 a에 해당하고 lr.intercept_는 b에 해당합니다.
따라서 x가 15일 때의 예측값은 15 * lr.coef_ + lr.intercept_로 계산됩니다. 이 값은 모델이 특정한 입력값에 대해 예측한 종속 변수의 값으로 해석할 수 있습니다.
- 50cm농어 데이터는 삼각형으로 표시
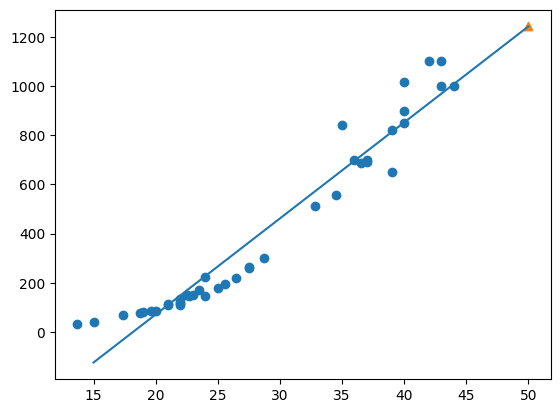
- 1차 방정식이 추세를 잘 표현했다고 볼 수 있다

- 훈련 세트의 R²점수
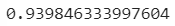
- 최근접 이웃으로 예측했던 것 보다 낮음
- 훈련 데이터에 과대적합되어있다

- 테스트 세트의 R²점수
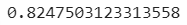
- 테스트세트 점수가 너무 낮다
- 과소적합되지 않았을까
* 어떤 모델이 과대/과소 적합됐는지는 여러 모델 / 실험을 통해 상대적으로 평가하는 것이 좋다
🧩 선형 모델의 단점

- 왼쪽 끝이 음수로 떨어지고 있다
- 치어를 넣고 예측하면 무게가 음수로 낮아질 수 있다?
- 현실적으로는 말이 안됨
- y절편(intercept_)이 음수로 나왔었음
- 직선보다는 2차함수로 만들었을 때 성능이 올라갈 것
👉🏻 다항회귀

- 무게(y) = a길이²(ax²) + b길이(bx) + c
- a, b, c에 해당하는 계수 구하기
* 이처럼 x의 다항식으로 구하는 선형 회귀를 다항회귀라고 한다
주로 데이터의 비선형 패턴을 모델링하기 위한 수학적인 선택이며, 이는 어떤 데이터의 실제 관계를 더 잘 표현하기 위한 것입니다. 제곱을 사용하는 것에는 몇 가지 수학적인 이유가 있습니다.
- 다항식 근사: 제곱을 사용하면 데이터를 잘 설명하는 다항식 근사를 할 수 있습니다. 다항식은 간단한 형태에서부터 매우 복잡한 형태까지 다양한 패턴을 표현할 수 있습니다.
- 곡선 표현: 제곱을 사용하면 데이터를 곡선 형태로 모델링할 수 있습니다. 많은 현상이 선형이 아닌 곡선 형태로 나타나기 때문에, 제곱을 통해 높은 차수의 다항식을 사용하면 곡선을 더욱 정확하게 표현할 수 있습니다.
- 비선형성 캡처: 제곱항을 추가함으로써 모델은 비선형적인 데이터 패턴을 캡처할 수 있습니다. 특히 농어의 무게와 길이 사이의 관계가 선형이 아니라 비선형일 때, 제곱항을 추가함으로써 그 비선형성을 포착할 수 있습니다.
- 패턴의 잘못된 예측 해결: 데이터의 패턴을 정확하게 예측하기 위해서는 선형 모델만으로는 한계가 있을 수 있습니다. 제곱항을 추가하면 데이터의 비선형적인 특성을 더 잘 예측할 수 있어서 모델의 정확성이 향상될 수 있습니다.
따라서, 제곱을 사용하는 것은 데이터의 특성을 더 정확하게 모델링하고자 하는 수학적인 선택이며, 이는 주로 데이터의 현상을 더 잘 표현하기 위한 것입니다.
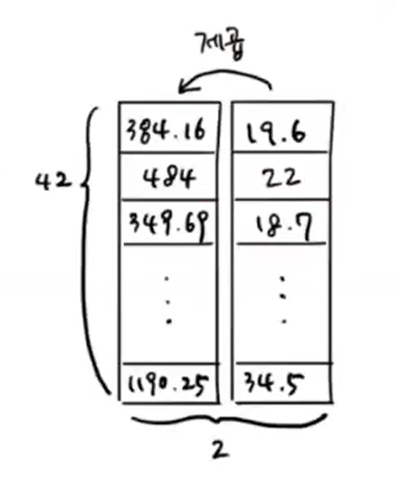
- 다항 회귀를 위한 클래스가 따로 있는 것은 아니고 x제곱항을 만들어 linear regression 클래스에 넣어주면
자동 구현된다
- 길이 제곱 항을 새로 만들어 추가해준다
- 길이에 대한 1차원 배열을 제곱한 배열을 추가
- 앞 뒤는 상관 없음

✅ np.column_stack
- 일차원 배열 두개를 나란히 붙임
넘파이의 column_stack 함수는 두 개 이상의 1차원 배열을 쌓아서 2차원 배열(행렬)을 만드는 함수입니다. 여러 개의 열(column)을 갖는 행렬을 만들 때 사용됩니다. 아주 간단한 예제를 통해 설명해보겠습니다.
예를 들어, 다음과 같이 두 개의 1차원 배열이 있다고 가정해봅시다:
import numpy as np
arr1 = np.array([1, 2, 3])
arr2 = np.array([4, 5, 6])이제 이 두 배열을 열 방향으로 쌓아서 2차원 배열을 만들고 싶다면 column_stack을 사용할 수 있습니다:
result = np.column_stack((arr1, arr2))여기서 (arr1, arr2)는 튜플로 배열들을 묶어주는 역할을 합니다.
결과로 얻게 되는 result는 다음과 같이 될 것입니다:
array([[1, 4],
[2, 5],
[3, 6]])이제 result는 두 배열을 열 방향으로 쌓아 만든 2차원 배열이 되었습니다. 첫 번째 열은 arr1의 원소들을, 두 번째 열은 arr2의 원소들을 갖고 있습니다.
이것으로 column_stack 함수의 간단한 사용법을 설명해보았습니다. 이 함수는 여러 배열을 합치는 데 유용하게 사용될 수 있습니다.
- 제곱은 그냥 파이썬의 **를 활용
- 배열에 있는 모든 원소에 전부 제곱이 적용됨
- 훈련세트와 테스트세트가 준비됨

- Linear Regression 클래스 객체를 만든다
- fit메서드를 활용해 학습을 시킨다
- target은 일반 선형회귀나 다항회귀나 변동이 없기 때문에 그대로 넣으면 된다

- 50cm 농어를 예측하기 위해서는 50**2항도 넣어줘야 한다
- x²항이 추가되었기 때문에
- 순서에 맞게 넣어줘야 한다
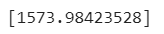
- 1.5kg로 예측을 함
- 계수와 절편 확인해보기
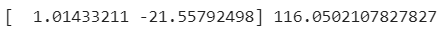
- 제곱항을 추가했기 때문에 계수가 두 개로 나옴
- 절편이 양수로 바뀜
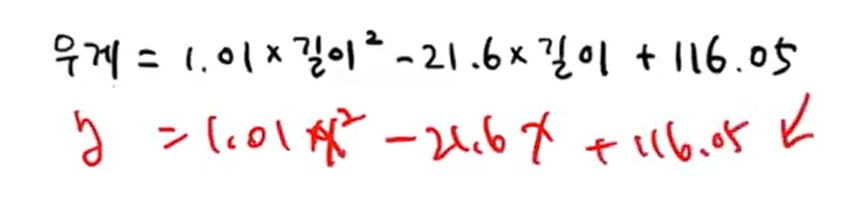
- 이런 이차함수를 훈련한 것으로 볼 수 있다

- 2차그래프를 그리는 방법은 직선을 잘게 쪼개서 조금씩 그리는 것이다 ↓

- 15 ~ 50까지 각각 1씩 자른 배열을 만든다 (point 배열) = x축의 point
- train_input과 train_target을 가지고 산점도를 그린다
- x축의 값은 point로 두고, y축 값은 앞에서 구한 2차방정식을 활용해 y축 point의 좌표를 구한다
- 아주 잘게 쪼갠 직선을 계속해서 그리게 된다
- 훈련 세트를 잘 표현하고 있음
- 길이가 늘어날 때 무게가 조금씩 더 많이 늘어나는 상승세



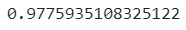
- 선형 회귀때보다 모델의 성능이 높아짐
- 하지만 테스트 점수가 조금 더 높아 조금 더 복잡한, 조금 더 과대적합 시킨 모델을 사용할 필요가 있음
- 지금은 우리가 특성을 하나(길이)만 사용했기 때문에 이렇게 그릴 수 있는 것
- 특성을 많이 사용하면 그래프로 확인하기 어려울 수 있어 score점수를 활용해야한다
✏️ QnA
🙋🏻♀️ 3차 다항 회귀를 사용하면 더 과대적합 될까요?
👩🏻🏫 그럴 수 있다. 변곡점이 두 개 그려지기 때문에 가능성이 있다
🙋🏻♀️ 과대 적합, 과소 적합을 판단할 때 결정 계수의 값이 높다의 기준은 보통 어느 정도일까요?
👩🏻🏫 문제마다 다르다. 어떤 것은 여러 모델을 써도 0.8 이상으로 올라가기 힘든 데이터 셋이 있고, 어떤 것은 0.99까지 도달할 수도 있다. 문제나 상황에 따라 다르고 절대적인 기준은 없다. 분류에서 정확도도 마찬가지. 예를 들어 텍스트 인식 등의 문제는 90%이상 넘을 수 있다 예상할 수 있다. 이는 여러 테스트나 연구 결과를 통해 예측할 수 있는 부분이다. 하지만 그렇지 않은 분야가 있고 그 분야마다 한계치가 있다. 상황마다 도메인마다 다를 수 있다
🙋🏻♀️ 실제 업무에서 R²값이 0.5만 나와도 높게 나온 값이라고 들은 기억이 있는데요, 강사님도 그런 경험이 있으신가요?
👩🏻🏫 0.5가 높게 나왔다고 본 적은 없는 것 같다. 해당 분야에서 0.5 이상이 얻기 어려운 데이터셋이라면 그럴 수 있지만 일반적으로는 그렇지 않다
🙋🏻♀️ 위의 문제에서 R²가 무엇을 뜻하는 것인가요?
👩🏻🏫 결정계수. 사이킷런에서 회귀 모델을 평가할 때 사용하는 대표적인 측정 방법 중 하나이다
🙋🏻♀️ 실무에서 메트릭을 변화시켜 R²가 유의미하게 변화하는 경우도 있을까요?
👩🏻🏫 R²값이 직관적으로 이해하기 쉽지 않다. 평균 제곱근 오차, 평균 절대값 오차 등을 사용해서 체감/가늠해볼 수 있고 R²를 변형해서 사용하는것은 없다
🙋🏻♀️ R²가 0.97이라는 것은 97% 정확한 모델이라는 건가요?
👩🏻🏫 전혀 아니다. 정확도가 아니다. 결정계수라는 계수가 타깃값과 얼마나 연관이 되는지를 측정하는 값이기 때문. 97%'정확하다' 등의 정확도는 분류 문제에서 나오는 것. 회귀모델은 정확도로 얘기할 수 없다. 평균 절댓값 오차 등의 지표를 사용해야한다
🙋🏻♀️ 도서 추천
👩🏻🏫
https://product.kyobobook.co.kr/detail/S000208981368
핸즈온 머신러닝 | 오렐리앙 제롱 - 교보문고
핸즈온 머신러닝 | 실무 밀착형 예제부터 스테이블 디퓨전 등 최신 머신러닝 트렌드까지 주요 인공 지능 콘퍼런스에서 전문가들이 소개한 최고의 실전 지침서 ** 독자의 편의를 고려한 분권(1권,
product.kyobobook.co.kr
https://product.kyobobook.co.kr/detail/S000061584677
케라스 창시자에게 배우는 딥러닝 | 프랑소와 숄레 - 교보문고
케라스 창시자에게 배우는 딥러닝 | 단어 하나, 코드 한 줄 버릴 것이 없다! 단 한 권의 딥러닝 책을 선택한다면 바로 이 책이다!케라스 창시자이자 구글 딥러닝 연구원인 저자는 ‘인공 지능의
product.kyobobook.co.kr
https://product.kyobobook.co.kr/detail/S000001810484
파이썬 라이브러리를 활용한 머신러닝 | 안드레아스 뮐러 - 교보문고
파이썬 라이브러리를 활용한 머신러닝 | 사이킷런 핵심 개발자에게 배우는 머신러닝 이론과 구현현업에서 머신러닝을 연구하고 인공지능 서비스를 개발하기 위해 꼭 학위를 받을 필요는 없습
product.kyobobook.co.kr
🙋🏻♀️ 팬클럽이나 스터디그룹?
👩🏻🏫 https://www.facebook.com/groups/tensorflowstudy
Facebook에 로그인
Notice 계속하려면 로그인해주세요.
www.facebook.com
출처: https://youtu.be/xkknXJeEaVA?si=SJ8zOZqnpLcIFoJw
'ML | DL > 혼자공부하는머신러닝딥러닝' 카테고리의 다른 글
| 9강. 로지스틱 회귀 알아보기 (0) | 2023.12.14 |
|---|---|
| 8강. 특성 공학과 규제 알아보기 (0) | 2023.12.07 |
| 6강. 회귀 문제를 이해하고 k-최근접 이웃 알고리즘으로 풀어 보기 (0) | 2023.11.15 |
| 5강. 정교한 결과 도출을 위한 데이터 전처리 알아보기 (0) | 2023.11.13 |
| 4강. 훈련 세트와 테스트 세트로 나누어 사용하기 (0) | 2023.11.08 |