01-3. 마켓과 머신러닝
👉🏻 첫 번째 머신러닝 프로그램
- 머신러닝을 한다 = 머신러닝 프로그램을 만든다
- 프로그램: 파이썬 등의 프로그래밍 언어를 사용한 무언가..?
👀 예) 한빛 마켓
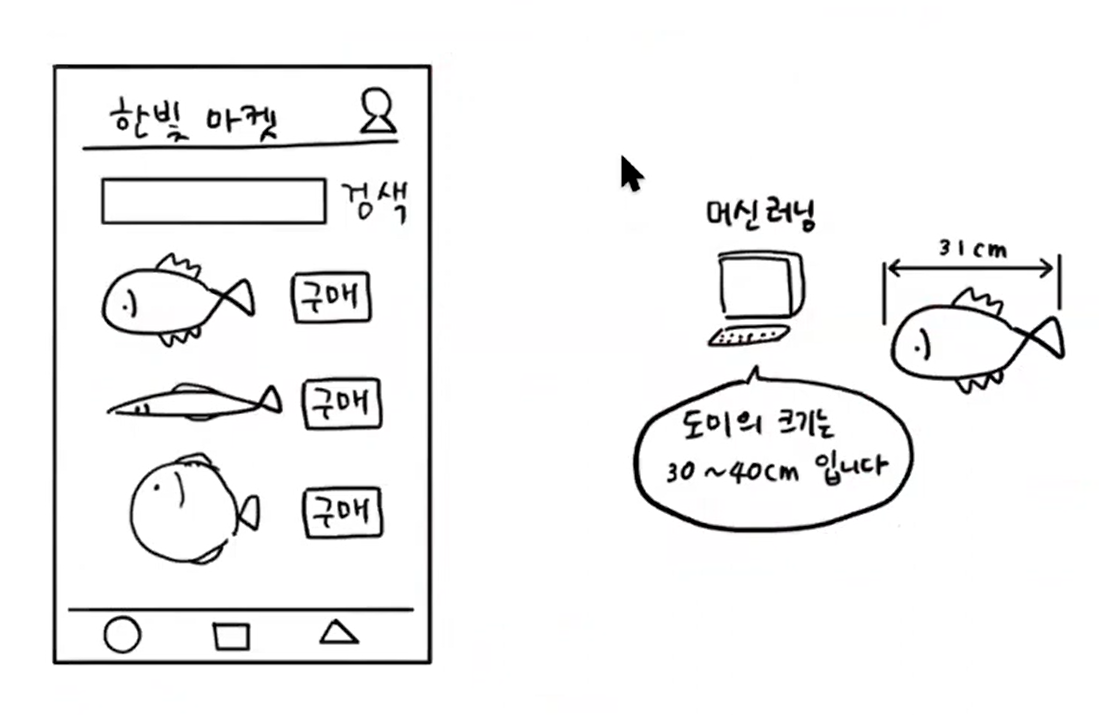
- 생선을 파는 모바일 쇼핑몰
- 직원이 생선을 구분을 못하니 생선을 자동 구분하는 머신러닝 프로그램을 만들기로 함
- 머신러닝 프로그램이 생선 데이터를 보고 도미라는 것을 판단
- 이 머신러닝 프로그램은 도미의 크기가 30 ~ 40 cm라는 것을 어떻게 알았을까?
👉🏻 전통적인 프로그램
- 누군가가 규칙이나 기준을 정해줌
- 프로그래머 당사가 규칙을 만들거나
- 팀 회의를 통해
- 기획자가 정해주거나
- 고객사 등 의뢰자가
- 거의 대부분의 프로그램
- 미리 규칙을 정하기 어려운 경우가 많다
- 이 때 머신러닝 프로그램을 사용한다

- 불변의 법칙을 제시하면 프로그램을 짤 수 있다
- 하지만 실제로는 생선이 30cm 이상이라고 무조건 도미라고 할 수 없다
- 그래서 머신러닝이 특정 생선이 도미인지 아닌지에 대한 규칙을 스스로 찾게 함
🧩 전통적 프로그램 vs 머신러닝 프로그램
- 전통적 프로그램
- 미리 규칙을 정함
- 그 규칙대로 프로그램을 작성
- 머신러닝 프로그램
- 프로그램을 만들어서 규칙을 찾게 한다
- 데이터에서 규칙을 찾는다 (학습, 훈련)
🧩 기본 용어
✅ 클래스 (class)
- 어떤 종류를 나타낼 때 클래스라고 함
✅ 분류 (classification)
- 클래스 중 하나를 구별해내는 문제
✅ 이진 분류 (binary classification)
- 2개의 클래스 중 하나를 고르는 문제
- 앞으로 나올 예제에서 도미 vs 빙어로 나뉘고 그 중 하나를 선택하는 것이 해당됨
👀 도미 데이터
https://gist.github.com/rickiepark/b37d04a95a42ef6757e4a99214d61697
도미의 길이, 무게 데이터
도미의 길이, 무게 데이터. GitHub Gist: instantly share code, notes, and snippets.
gist.github.com

- bream_length: 길이
- bream_weight: 무게
- 첫 번째 도미의 데이터: 길이는 25.4cm, 무게는 242.0g
✅ 샘플
- 머신러닝이 참고하는 데이터
- example, observation
- 각각의 생선 데이터를 샘플이라고 한다
- 이 도미 데이터는 35개의 샘플이 있다
✅ 특성
- 데이터의 특징
- 속성 등 책이나 저자마다 표현 방식이 다를 수 있다
- 각 도미의 특징(길이와 무게)를 특성이라고 한다
🧩 산점도 그려보기
- scatter plot
- x축과 y축에 2개의 특성을 놓고 각 샘플을 하나의 점으로 표시

- import문을 통해 matplotlib.pyplot을 불러 오고 plt로 부르겠다고 선언 (약어는 규칙적)
- plt로 라이브러리를 호출하며 함수 사용
- scatter() 함수를 사용해 산점도를 그림, ()안에는 순서대로 x축, y축 데이터
- 축이름 표시 위해 xlabel과 ylabel 사용
- 출력을 위해 plt.show() 사용

- 바꿔그려도 상관은 없음
- 각 점이 도미 데이터 하나를 의미
- 길이가 늘어나면 무게도 늘어나는 것을 볼 수 있다
👀 빙어 데이터
https://gist.github.com/rickiepark/1e89fe2a9d4ad92bc9f073163c9a37a7
빙어의 길이, 무게 데이터
빙어의 길이, 무게 데이터. GitHub Gist: instantly share code, notes, and snippets.
gist.github.com
- 14개의 샘플

- scatter 함수를 두 번 연속으로 호출하면 하나의 산점도에 두 개의 데이터를 중첩해서 보여준다
- 자동으로 색을 다르게 해서 보여준다 (파랑: 도미, 주황: 빙어)

- 도미에 비해 빙어가 작은 것을 알 수 있다
👀 도미와 빙어 합치기

- 도미의 길이, 빙어의 길이 / 도미의 무게, 빙어의 무게를 하나의 파이썬 리스트로 합쳐야 한다
- 그래야 머신러닝 프로그램이 분류할 수 있다
- 만약 하나의 데이터만 넣으면 구분할 수 있는 법을 배울 수 없다
- 일반화 능력 향상: 데이터를 하나로 합치면 모델은 두 종류의 물고기 데이터를 동시에 학습하고, 이로써 두 클래스 간의 차이를 보다 명확하게 파악할 수 있습니다. 이는 모델의 일반화 능력을 향상시킬 수 있습니다.
- 모델 성능 향상: 데이터를 하나로 합침으로써 모델이 도미와 빙어를 구분하는 데 도움이 됩니다. 데이터를 분리하여 모델을 훈련하는 경우, 모델은 도미와 빙어 데이터를 독립적으로 처리하게 되며, 두 클래스 간의 상관 관계를 파악하기 어려울 수 있습니다.

- 리스트 변수에 덧셈 연산자를 쓰면 두 리스트가 붙여져 하나의 리스트가 된다
- 여기서 끝이 아니라 사이킷런이 기대하는 데이터 형태로 만들어줘야 한다
- 리스트 안의 리스트 형태 (이차원 배열)
- 내부 리스트에는 한 샘플의 길이와 무게가 담기도록
🧩 리스트 내포

- 대괄호로 리스트를 만듦
- 리스트 안에 for문
- length와 weight에서 데이터를 하나씩 꺼내와 l과 w에 할당하여 내부 리스트를 만든다
- 그것을 외부 리스트에 추가한다

- print로 확인해보면 잘 묶인 것을 볼 수 있다
👉🏻 정답 준비
- 어떤 것이 도미이고 어떤 것이 빙어인지 fish_data에 포함되어 있지 않다
- 어떤 것이 도미이고 어떤 것이 빙어인지 알려주지 않으면 머신러닝이 학습할 수 없다
- 규칙을 찾게 해야하는데 정답을 알려주지 않으면 규칙을 찾을 수 없다
- 지도학습

- 파이썬의 연산자 오버로딩을 사용

- 1 원소 35개, 0 원소 14개가 담긴 리스트를 생성
- 거의 모든 머신러닝 라이브러리는 이진 분류의 경우 정답을 0 아니면 1로 표시한다
- 찾으려는 대상이 아닌 빙어를 0, 찾으려는 대상인 도미를 1로 놔둠
👉🏻 k - 최근접 이웃
- 어떤 데이터에 대한 답을 구할 때 주위의 다른 데이터를 보고 다수를 차지하는 것을 정답으로 사용
- 근묵자흑
- 주위의 데이터로 현재 데이터를 판단
- 주위 클래스를 정답 클래스로 판단
- k는 주위에 바라볼 이웃 수, 기본 값은 5
k-최근접 이웃(K-Nearest Neighbors, k-NN) 알고리즘은 머신러닝에서 사용되는 간단하면서 효과적인 분류 및 회귀 알고리즘 중 하나입니다. 초보자도 이해하기 쉽게 설명해 드리겠습니다.
K-최근접 이웃 알고리즘의 핵심 아이디어:
1. 이웃들을 봅니다: K-최근접 이웃 알고리즘은 "주변에 있는 이웃들이 어떤 것인가?"에 초점을 둡니다. 이웃들은 데이터 포인트들을 의미합니다.
2. 분류 또는 회귀: 주어진 데이터 포인트가 분류 또는 회귀 문제인지에 따라 알고리즘의 목적이 달라집니다.
- 분류(Classification): 주어진 데이터 포인트를 어떤 카테고리(클래스)에 속하는지 판단합니다. 예를 들어, 고양이인지 강아지인지 분류합니다.
- 회귀(Regression): 주어진 데이터 포인트에 대한 수치 예측을 수행합니다. 예를 들어, 주택 가격을 예측합니다.
3. K의 선택: K는 이웃의 수를 나타냅니다. 주어진 데이터 포인트 주변에서 몇 개의 가장 가까운 이웃을 볼 것인지 결정해야 합니다. K 값은 사용자가 설정하며, 작은 K 값은 모델을 민감하게 만들고, 큰 K 값은 모델을 둔감하게 만듭니다.
4. 거리 측정: 이웃들을 선택할 때, 데이터 포인트 간의 거리를 측정합니다. 일반적으로 유클리드 거리(Euclidean Distance)를 사용하지만, 다른 거리 측정 방법도 가능합니다.
K-최근접 이웃 알고리즘 동작 방식:
1. 주어진 데이터 포인트와 모든 데이터 포인트 간의 거리를 계산합니다.
2. 거리가 가장 가까운 K개의 이웃을 선택합니다.
3. 분류 문제의 경우, 이 K개의 이웃 중 가장 많은 카테고리를 가진 이웃의 카테고리로 주어진 데이터 포인트를 분류합니다. 회귀 문제의 경우, K개 이웃의 값을 평균내어 예측값을 얻습니다.
K-최근접 이웃 알고리즘은 직관적이고 이해하기 쉬우며, 많은 상황에서 잘 작동합니다. 그러나 데이터의 차원이 높거나 대규모 데이터셋에서는 계산 비용이 높아질 수 있으므로 적절한 K 값과 거리 측정 방법을 선택하는 것이 중요합니다.

- 사이킷 런의 sklearn.neighbors모듈 밑에 KNeighborsCalssifier라는 클래스로 K-최근접 이웃이 구현되어 있다
- 클래스 사용 시 ()를 통해 클래스 인스턴스(클래스 객체)를 만들어 변수에 할당한다
생각해보세요, 머신러닝 모델은 하나의 도구나 기계와 같습니다. 그 도구를 만들 때, 우리는 그 도구가 어떻게 동작하고 어떻게 설정되어야 하는지에 대한 설계도를 그립니다. 이 설계도가 바로 클래스입니다.
클래스를 만들 때, 우리는 모델의 구조, 규칙, 그리고 조작 방법을 정의합니다. 예를 들어, 모델이 어떤 데이터를 입력으로 받고, 그 데이터를 어떻게 처리하며, 결과를 어떻게 내뱉어야 하는지를 정합니다. 이런 설계를 클래스로 표현합니다.
그리고 이렇게 만든 모델 설계도를 사용하여 실제로 모델을 만들 수 있습니다. 클래스 인스턴스를 만들면, 그것이 모델의 한 부분이 되는 것이죠. 그리고 우리는 이 모델을 다양한 데이터나 작업에 사용할 수 있습니다.
예를 들어, 물고기를 구분하는 모델을 만든다고 상상해보세요. 클래스를 만들면 그 모델이 어떤 규칙으로 물고기를 구분하는지를 정의합니다. 그런 다음, 이 모델을 여러 번 사용해서 다양한 물고기를 구분하거나 새로운 물고기를 구분하는데 사용할 수 있습니다.
이 모델을 클래스로 만든 이유는, 모델을 효율적으로 관리하고 재사용하려고, 그리고 모델을 만들 때 필요한 규칙과 구조를 명확하게 정의하기 위해서입니다. 변수에 할당하는 이유는 그 모델을 쉽게 찾아서 사용하고 조작할 수 있게 하기 위해서입니다. 그래서 모델을 만들고 사용할 때 클래스를 사용하는 것이 유용합니다.
- fish_data와 fish_target을 kn객체의 fit()메서드에 전달
- fit()은 두 데이터를 가지고 머신러닝 모델을 훈련함, 다른 클래스에서도 사용됨
- kn을 머신러닝 모델이라고 함
- 머신러닝 프로그램의 알고리즘이 객체화 된 것을 모델이라고 한다
- 알고리즘 자체를 모델이라고 하기도 한다
- 얼만큼 잘 학습되었는지 socre()메서드로 확인할 수 있다. (정확도, accuracy)

- 100% 다 맞췄다는 의미
- 이미 사이킷런에 짜여 있는 클래스를 가져다가 구현한 것
- 직접 알고리즘을 구현하고 있는 것은 아님
👀 새로운 생선 예측
- 길이는 30cm이고 무게가 600g인 새로운 생선이 들어왔을 때

- predict() 메서드를 활용해 예측을 한다, 사이킷런 내의 다른 클래스에서도 마찬가지
- 훈련데이터를 주었을 때 이차원 데이터로 주었기 때문에 예측 데이터도 이차원으로 줘야 한다

- 1이라고 출력된다
- 우리가 1을 도미라고 정했기 때문에 도미라고 판단한 것을 알 수 있다
- 사이킷런이 numpy array 타입으로 반환해서 array()가 붙은 것
산점도 상에서 나타냈을 때

🧩 k의 개수 늘려보기

- n_neighbors 매개변수를 사용해서 변경해줄 수 있다
- 변경하면 정확도가 달라진다
- 지금 49로 해 놓은 건 전체 샘플을 다 보는 것
- 전체 샘플의 다수는 도미. 이렇게 만들어 놓으면 무조건 다 도 미라고 예측한다
- 앞에서와 같이 fit()으로 훈련
- score()를 통해 점수를 출력

- 천체 샘플 49개 중에 35개가 도미

- 도미만 도미라고 정확히 예측
- 빙어는 도미라고 잘못 예측
- 71%의 정확도
출처: https://youtu.be/GOCVVSMeIf8?si=mAyJrjOBV0mWDB1H
'ML | DL > 혼자공부하는머신러닝딥러닝' 카테고리의 다른 글
| 7강. 사이킷런으로 선형 회귀 모델 만들어 보기 (0) | 2023.11.27 |
|---|---|
| 6강. 회귀 문제를 이해하고 k-최근접 이웃 알고리즘으로 풀어 보기 (0) | 2023.11.15 |
| 5강. 정교한 결과 도출을 위한 데이터 전처리 알아보기 (0) | 2023.11.13 |
| 4강. 훈련 세트와 테스트 세트로 나누어 사용하기 (0) | 2023.11.08 |
| 1~2강. 인공지능, 머신러닝 그리고 딥러닝이란 무엇인가? | 코랩과 주피터 노트북으로 손코딩 준비하기 (1) | 2023.11.02 |