6강. 회귀 문제를 이해하고 k-최근접 이웃 알고리즘으로 풀어 보기
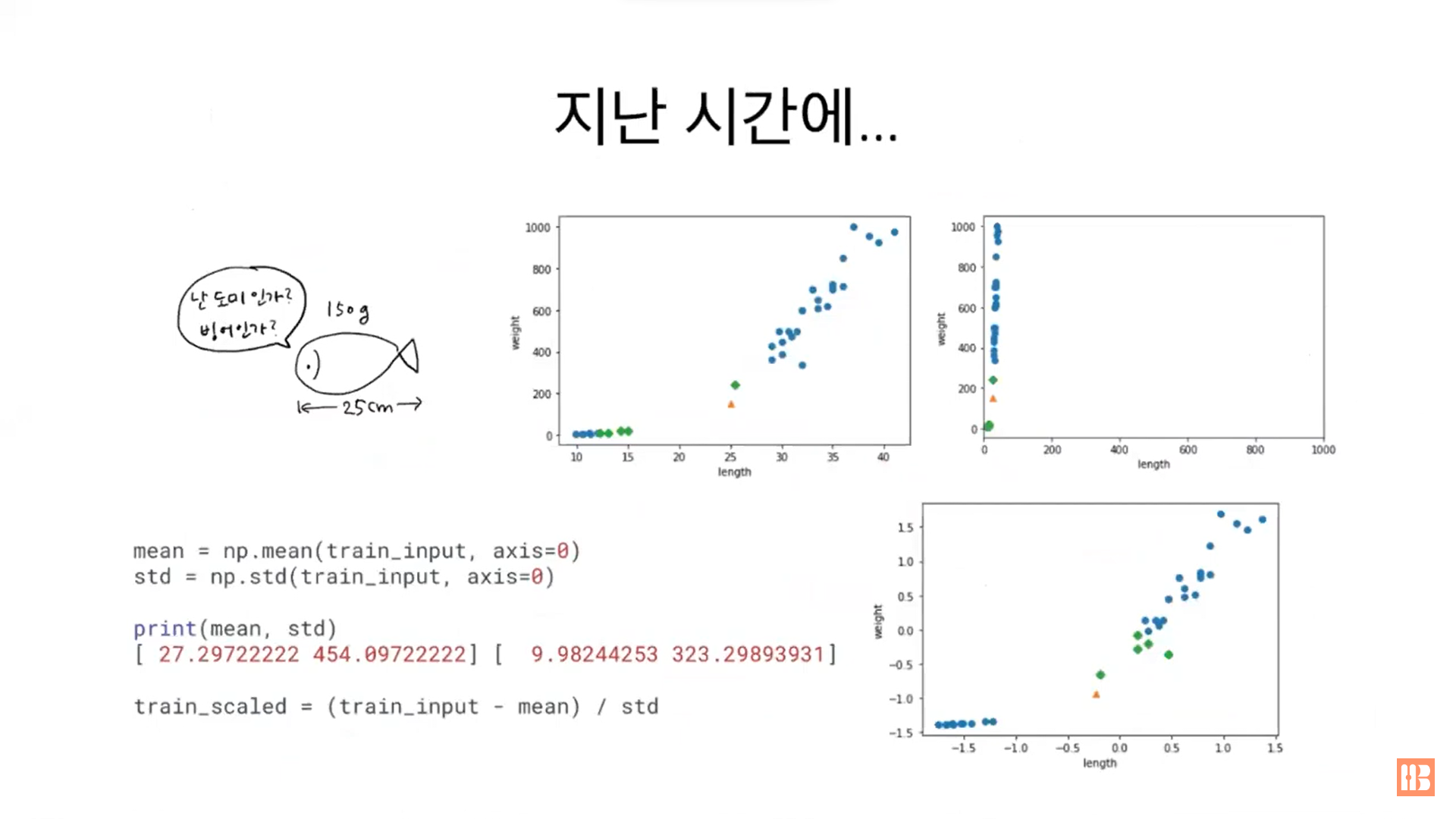
03-1. k- 최근접 이웃 회귀 * 25cm, 150g짜리 생선 = 도미인데 빙어로 분류됨 * kneighbors()를 통해 이상한 도미의 최근접 이웃을 찾아봄 → 하나만 도미, 나머지는 빙어 * 이유는 x축과 y축의 스케일이 달라서!!! * 조정후 살펴보니 x축으로는 데이터가 퍼지지 않고 y축을 따라서 데이터가 분포되어 있다 → 무게 특성이 영향을 많이 준다는 것 * 특성의 스케일을 맞춰줘야 특정 특성에 알고리즘이 좌지우지 되지 않는다 * 데이터전처리 - 스케일 조정 中 표준점수 (z점수) * 테스트할 데이터도 훈련세트의 평균과 표준편차를 이용해 표준 점수를 구해야 한다 * 거리에 민감한 알고리즘: k-최근접 이웃, 회귀 알고리즘들, 딥러닝 알고리즘들 / 전처리 필수!!! * 트리기반 알고리즘은 거리..